Learn how to create a complete backup solution for your Open edX installation. This detailed step-by-step how-to guide covers backing up MySQL and MongoDB, organizing backup data into a single date-stamped tarball zip file, plus how to setup a cron job and how to copy your backups to an AWS S3 storage bucket.
Summary
The official Open edX documentation takes a laissez faire approach to many aspects of administration and support, including for example, how to properly backup and restore course and user data. This article attempts to fill that void. Implementing an effective backup solution for Open edX requires proficiency in a number of technologies, which is fine if you’re part of a full IT team at a major university, but can this can otherwise be a real obstacle to competently supporting your Open edX platform.
Open edX stores course data, including media uploads such as images and mp4 video files in MongoDB. To do this, MongoDB’s core functionality is extended with a technology called GridFS that provides an infinitely scalable file system for all course-related data. For student data Open edX takes a more relational approach with MySQL, noting however that the Open edX platform relies on several databases (see right-hand diagram). These are excellent architectural choices and both technologies are best-of-breed and getting better all the time. Nonetheless, having two entirely different persisting strategies under the hood really complicates simple IT management responsibilities like data backups.
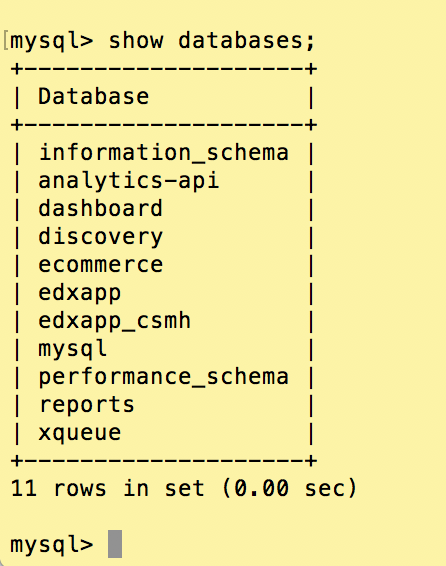
We’re going to setup an automated daily backup procedure that backs up the complete contents of the MongoDB course database (including file/document, media and image uploads) and each individual MySQL database that contains learner user data. We’ll create a Bash script that combines these files into a single date-stamped linux tarball and then pushes this to an AWS S3 bucket for long-term remote storage.
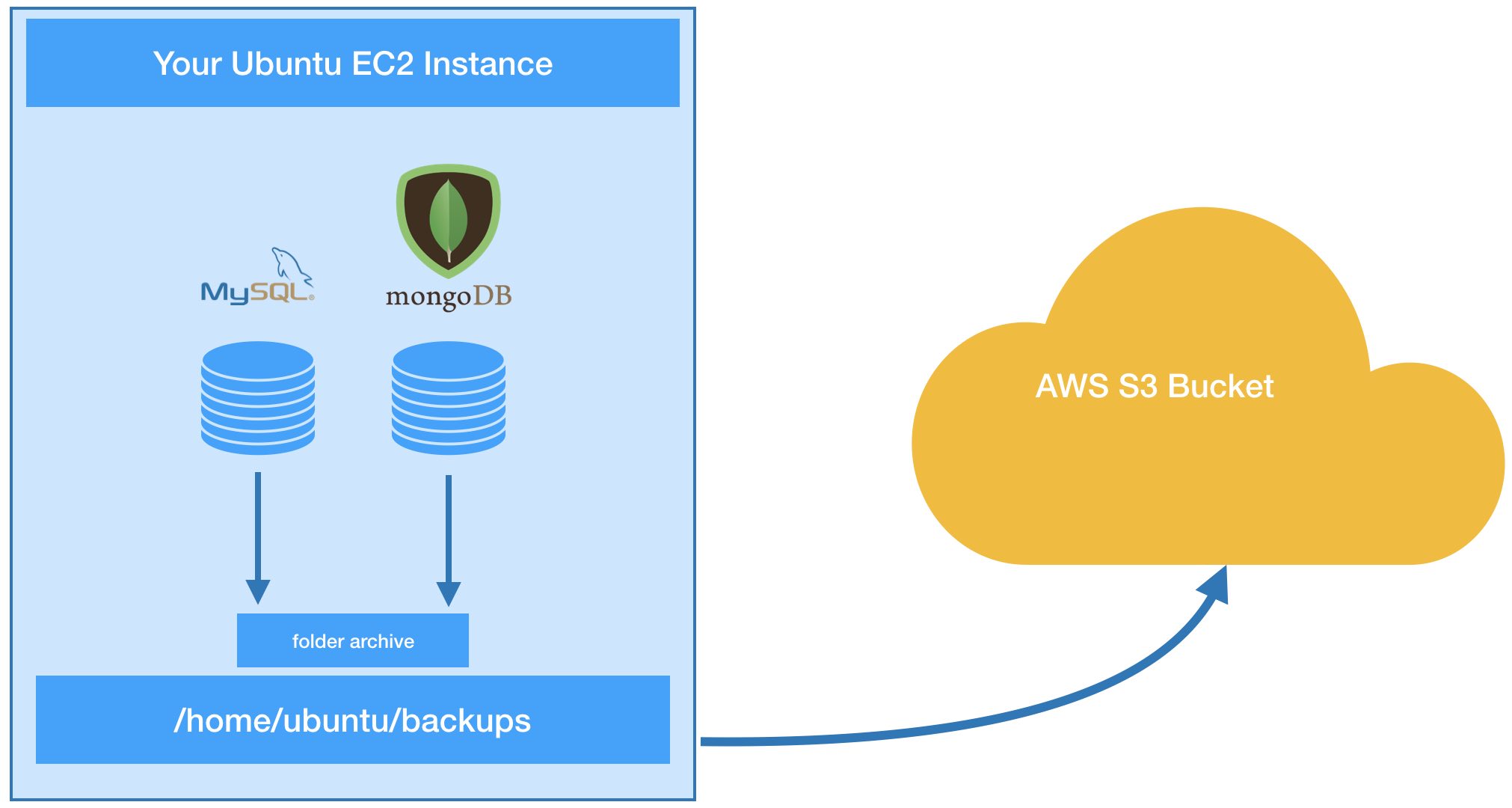
Implementation Steps
- Your Open edX instance is running from an AWS account
- Your AWS EC2 instance is running on an Ubuntu 16.04 LTS server built from the Amazon Linux AMI
- You have SSH access to your EC2 instance and sudo capability
- You have permissions to create AWS IAM users and S3 resources
- Your Open edX instance is substantially based on the guidelines published here: Native Open edX Ubuntu 16.04 64 bit Installation
AWS provides an integrated security management system called Identity and Access Management (IAM) that we are going to use in combination with AWS’ Command Line Interface (CLI) to give us a way to copy files from our local Ubuntu file system to an S3 bucket in our AWS account. If you’re new to either topic then it behooves you to follow these two links to learn the basics of both topics.
In this step, we’ll create a new IAM user with full access to S3 resources.
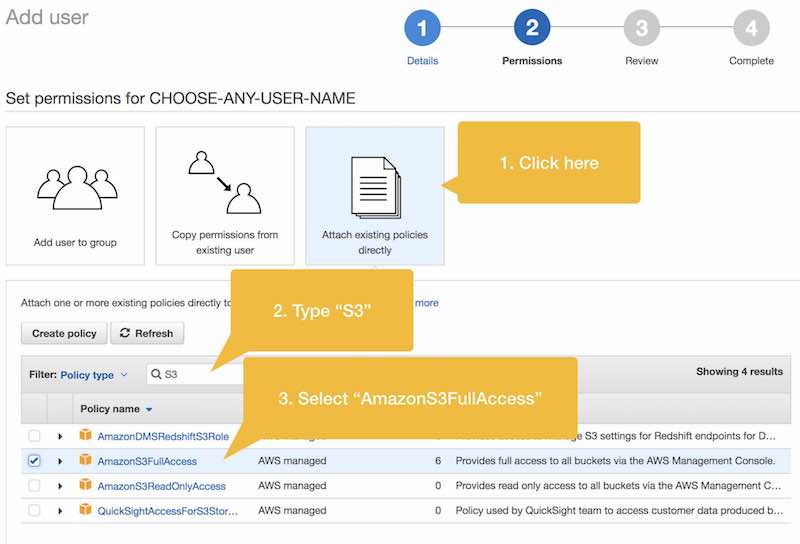
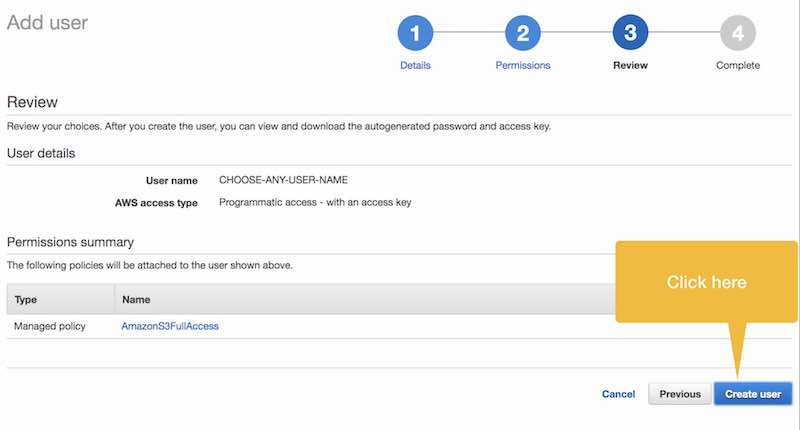
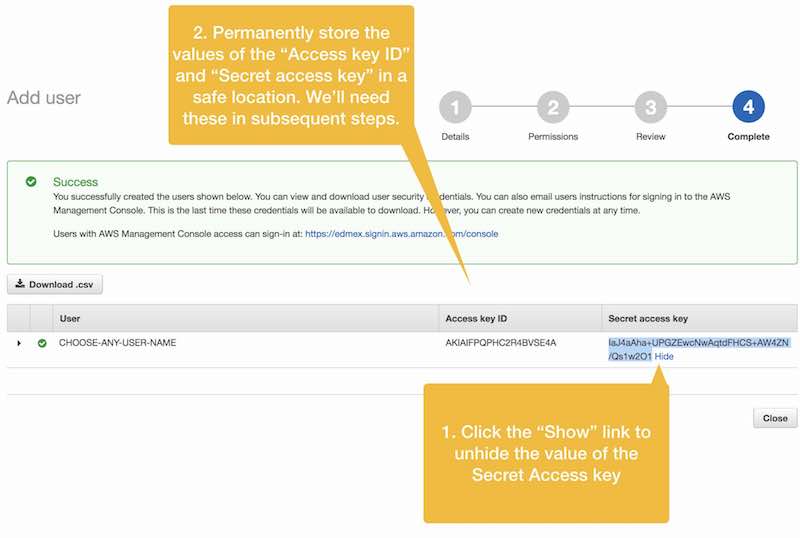
In the next step we’ll permanently store our “Access Key ID” and “Secret key ID” values in the AWS CLI configuration file on our Ubuntu server instance so that we’ll be able to seamlessly make calls to AWS S3 from the command line, and importantly, from a Bash script.
Next, lets install AWS’ command line tools. The version of Ubuntu that you should be using has Pip preloaded. We’ll use this to install AWS CLI.
$ pip install awscli --upgrade --user
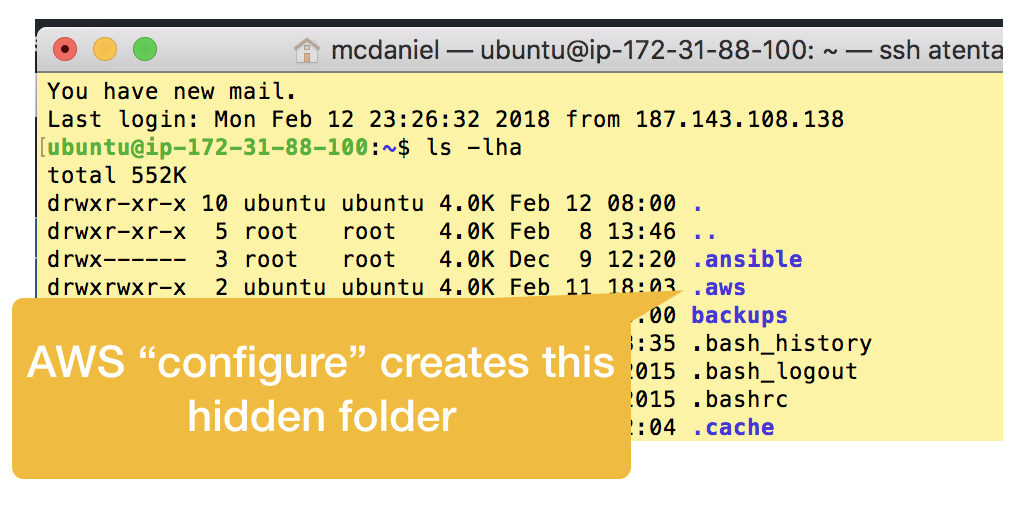
after installing run the AWS “configure” program to permanently store your IAM user credentials
$ aws configure
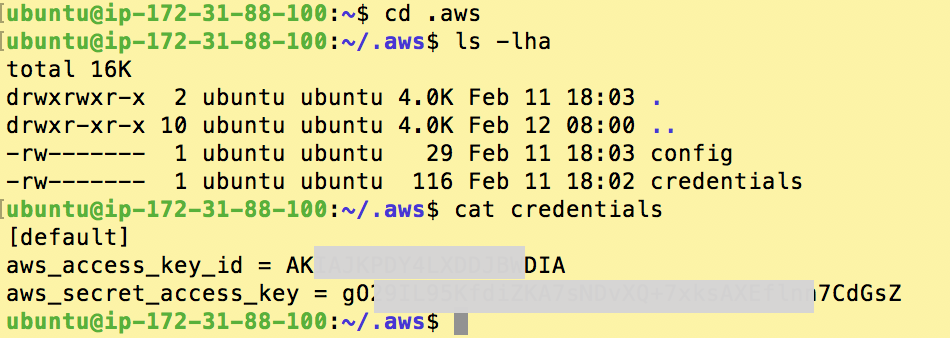
The “configure” program adds a hidden directory to your home folder named .aws that contains a file named “config” and another named “credentials”; both of which you can edit. So just fyi, you can change your configuration values in the future either by re-running aws configure or by editing these two files.
If you need to troubleshoot, or heck, if you just want to know more then you can read AWS’ CLI installation instructions.
Amazon S3 is object storage built to store and retrieve any amount of data from anywhere – web sites and mobile apps, corporate applications, and data from IoT sensors or devices. It is designed to deliver 99.999999999% durability, and stores data for millions of applications used by market leaders in every industry. We’ll use S3 to archive our backup files. In my view S3 is a very stripped down file system that has been highly optimized for its specific use case.
Creating an S3 bucket is straightforward, and AWS’ step-by-step instructions are very good. There are no special configuration requirements for our use case as a permanent file archive, so feel free to create your bucket however you like. You’ll reference your new S3 bucket in the next step.
Let’s do a simple test to ensure that a) AWS CLI is correctly installed and configured and b) your AWS S3 bucket is accessible from the command line. We’ll create a small test file in your home folder, then call the AWS CLI “sync” command to copy it to your bucket.
cd ~ echo "hello world" > test.file aws s3 sync test.file s3://[THE NAME OF YOUR BUCKET]
If successful then you’ll find a copy of your file inside your AWS S3 bucket. Otherwise, please leave comments describing your particular situation so that I can continue to improve this how-to article.
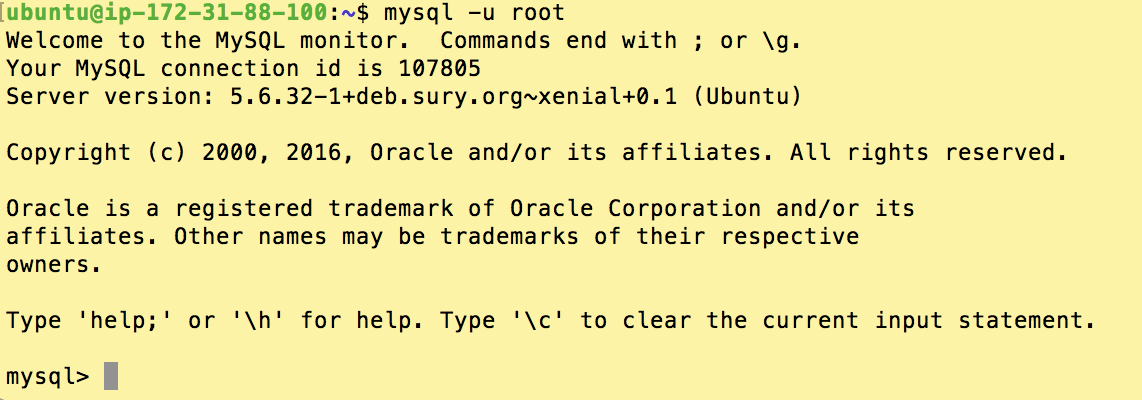
In this step we want to verify that you can connect to your MySQL server from the command line. If you are running an Open edX instance based on the Native Open edX Ubuntu 16.04 64 bit Installation then your MySQL server is running on your EC2 instance and is therefore accessible as “localhost”, which incidentally is the default host value. Additionally, the password value for the root MySQL account will not have been set unless you yourself did this afterward. If this is all true then you should be able to connect to MySQL with the following command
mysql -u root
If successful you’ll see a screen substantially like the following. Type ‘exit’ and enter to logout of MySQL. Please leave me a comment if you have trouble logging in so that I can improve this article.
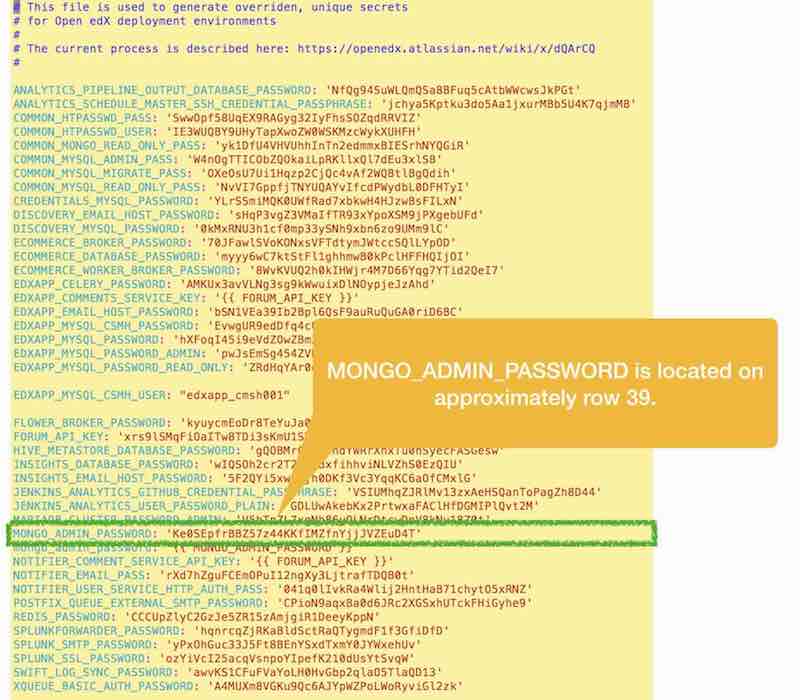
To connect to MongoDB you’ll need your admin password. The third step of the Open edX native build installation script creates a plain text file in your home folder named my-passwords.yml that contains a list of all unique password values that were automagically created for you during the installation. Your MongoDB admin password is located in this file on approximately row 39 and identified as MONGO_ADMIN_PASSWORD.
Next, we’ll create a small Bash script to test whether we can connect to MongoDB, as follows
#!/bin/bash for db in edxapp cs_comment_service_development; do echo "Dumping Mongo db ${db}..." mongodump -u admin -p'ADD YOUR PASSWORD HERE' -h localhost --authenticationDatabase admin -d ${db} --out mongo-dump done
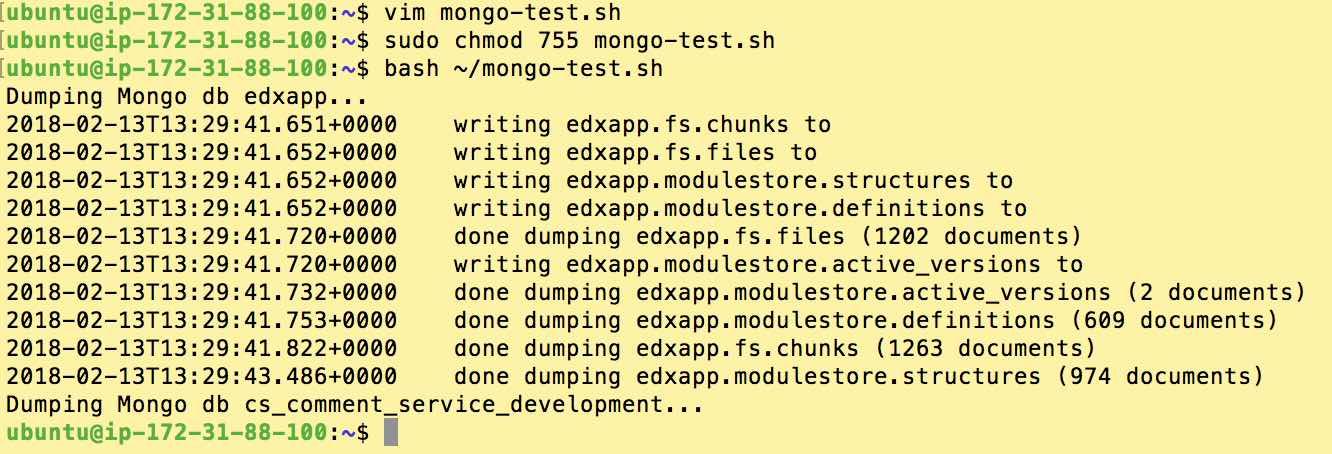
Save this in a file named ~/mongo-test.sh, then run the following commands to execute your test
sudo chmod 755 ~/mongo-test.sh #This makes the file executable bash ~/mongo-test.sh #execute the Bash script
If successful you’ll see output approximately like the following

In this step we’ll bring everything together into a single Bash script that does the following
- Creates a temporary working folder
- Backs up schemas and data for each database that is part of the Open edX platform. Importantly, we want to exclude system database in order to avoid data restore problems
- Backs up MongoDB course data and Discussion Forum data
- Combines both sets of data into a tarball
- Copies the tarball to our AWS S3 bucket
- Prunes our AWS S3 bucket of old backup files
- Cleans up and removes our temporary working folder
The complete script is available here on Github, or if you’re in a hurry just copy/paste the snippet below.
Credit for the substance of this script goes to Net Batchelder.
Credit for the substance of this script goes to Net Batchelder.
#!/bin/bash #--------------------------------------------------------- # usage: backup MySQL and MongoDB data stores # combine into a single tarball, store in "backups" folders in user directory # # reference: https://github.com/edx/edx-documentation/blob/master/en_us/install_operations/source/platform_releases/ginkgo.rst #--------------------------------------------------------- BACKUPS_DIRECTORY="/home/ubuntu/backups/" WORKING_DIRECTORY="/home/ubuntu/backup-tmp/" if [ ! -d "$WORKING_DIRECTORY" ]; then mkdir "$WORKING_DIRECTORY" echo "created backup working folder ${WORKING_DIRECTORY}" fi if [ -f "$WORKING_DIRECTORY/*" ]; then sudo rm -r "$WORKING_DIRECTORY/*" fi cd "$WORKING_DIRECTORY" #Backup MySQL databases MYSQL_CONN="-uroot" echo "Reading MySQL database names..." mysql ${MYSQL_CONN} -ANe "SELECT schema_name FROM information_schema.schemata WHERE schema_name NOT IN ('mysql','information_schema','performance_schema')" > /tmp/db.txt DBS="--databases $(cat /tmp/db.txt)" NOW="$(date +%Y%m%dT%H%M%S)" SQL_FILE="mysql-data-${NOW}.sql" echo "Dumping MySQL structures..." mysqldump ${MYSQL_CONN} --add-drop-database --no-data ${DBS} > ${SQL_FILE} echo "Dumping MySQL data..." # If there is table data you don't need, add --ignore-table=tablename mysqldump ${MYSQL_CONN} --no-create-info ${DBS} >> ${SQL_FILE} echo "Done backing up MySQL" #Backup Mongo for db in edxapp cs_comment_service_development; do echo "Dumping Mongo db ${db}..." mongodump -u admin -p'YOUR PASSWORD HERE' -h localhost --authenticationDatabase admin -d ${db} --out mongo-dump-${NOW} done echo "Done backing up MongoDB" #Check to see if a backups/ folder exists. if not, create it. if [ ! -d "$BACKUPS_DIRECTORY" ]; then mkdir "$BACKUPS_DIRECTORY" echo "created backups folder ${BACKUPS_DIRECTORY}" fi #Tarball all of our backup files tar -czf /home/ubuntu/backups/openedx-data-${NOW}.tgz ${SQL_FILE} mongo-dump-${NOW} sudo chown ubuntu /home/ubuntu/backups/openedx-data-${NOW}.tgz sudo chgrp ubuntu /home/ubuntu/backups/openedx-data-${NOW}.tgz echo "Created tarball of backup data openedx-data-${NOW}.tgz" #Prune the Backups/ folder by eliminating all but the 30 most recent tarball files if [ -d "$BACKUPS_DIRECTORY" ]; then cd "$BACKUPS_DIRECTORY" ls -1tr | head -n -15 | xargs -d '\n' rm -f -- fi #Remove the working folder echo "Cleaning up" sudo rm -r "$WORKING_DIRECTORY" echo "Sync backup to AWS S3 backup folder" aws s3 sync /home/ubuntu/backups s3://[ADD YOUR BUCKET NAME] echo "Done!"
Lets setup a cron job that executes our new backup script once a day at say, 6:00am GMT.
crontab -e
Then add this row to your cron table
# m h dom mon dow command 0 6 * * * sudo ./edx.backup.sh > edx.backup.out
And now you’re set! Your Open edX site is getting completely backed up every day and stored offset in an AWS S3 bucket.