The following is a soup to nuts walkthrough of how to set up and deploy a Django application to Amazon Web Services (AWS) all while remaining sane.
Tools/technologies used:
Now with Python 3! Check out the updated version of this article here.
This article has been updated to cover deploying with Python 3 because AWS now has tons of love for Python 3.
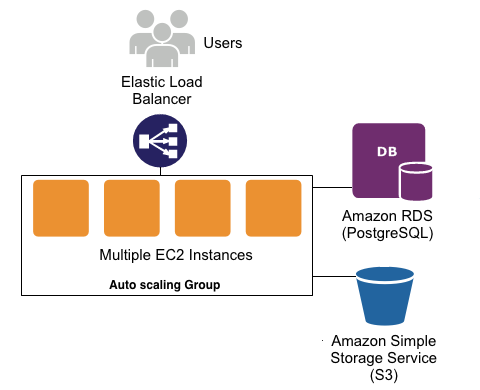
Elastic Beanstalk vs EC2
Elastic Beanstalk is a Platform As A Service (PaaS) that streamlines the setup, deployment, and maintenance of your app on Amazon AWS. It’s a managed service, coupling the server (EC2), database (RDS), and your static files (S3). You can quickly deploy and manage your application, which automatically scales as your site grows. Check out the official documentation for more information.
Getting Started
We’ll be using a simple “Image of the Day” app, which you can grab from this repository:
$ git clone https://github.com/realpython/image-of-the-day.git
$ cd image-of-the-day/
$ git checkout tags/start_here
After you download the code, create a virtualenv and install the requirements via pip:
$ pip install -r requirements.txt
Next, with PostgreSQL running locally, setup a new database named
iotd. Also, depending upon your local Postgres configuration, you may need to update the DATABASESconfiguration in settings.py.
For example, I updated the config to:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'iotd',
'USER': '',
'PASSWORD': '',
'HOST': 'localhost',
'PORT': '5432',
}
}
Now you can set up the database schema, create a superuser, and run the app:
$ python manage.py migrate
$ python manage.py createsuperuser
$ python manage.py runserver
Navigate to the admin page in your browser at http://localhost:8000/admin and add a new image, which will then be displayed on the main page.
The application isn’t meant to be very exciting; we’re just using it for demo purposes. All it does is let you upload an image via the admin interface and display that image full screen on the main page. That said, although this is a relatively basic app, it will still allow us to explore a number of “gotchas” that exist when deploying to Amazon Beanstalk and RDS.
Now that we have the site up and running on our local machine, let’s start the Amazon deployment process.
CLI for AWS Elastic Beanstalk
To work with a Amazon Elastic Beanstalk, we can use a package called awsebcli. As of this writing the latest version of is 3.0.10 and the recommended way to install it is with pip:
$ pip install awsebcli
Do not use brew to install this package. As of this writing, it installs v2.6.3 which is broken in subtle ways that will lead to serious frustration.
Now test the installation to make sure it’s working:
$ eb --version
This should give you a nice 3.x version number:
EB CLI 3.0.10 (Python 2.7.8)
To actually start using Elastic Beanstalk you will need an account with AWS (surprise!). Sign up (or log in).
Configure EB – Initialize Your App
With the AWS Elastic Beanstalk CLI working, the first thing we want to do is create a Beanstalk environment to host the application on. Run this from the project directory (“image-of-the-day”):
$ eb init
This will prompt you with a number of questions to help you configure your environment.
Default region
Choosing the region closest to your end users will generally provide the best performance. Check out this map if you’re unsure which to choose.
Credentials
Next, it’s going to ask for your AWS credentials.
Here, you will most likely want to set up an IAM User. See this guide for how to set one up. If you do set up a new user you will need to ensure the user has the appropriate permissions. The simplest way to do this is to just add “Administrator Access” to the User. (This is probably not a great choice for security reasons, though.) For the specific policies/roles that a user needs in order to create/manage an Elastic Beanstalk application, see the link here.
Application name
This will default to the directory name. Just go with that.
Python version
Next, the CLI should automagically detect that you are using Python and just ask for confirmation. Say yes. Then you need to select a platform version. Select
Python 2.7.
SSH
Say yes to setting up SSH for your instances.
RSA Keypair
Next, you need to generate an RSA keypair, which will be added to your ~/.ssh folder. This keypair will also be uploaded to the EC2 public key for the region you specified in step one. This will allow you to SSH into your EC2 instance later in this tutorial.
What did we accomplish?
Once
eb init is finished, you will see a new hidden folder called .elasticbeanstalk in your project directory:├── .elasticbeanstalk
│ └── config.yml
├── .gitignore
├── README.md
├── iotd
│ ├── images
│ │ ├── __init__.py
│ │ ├── admin.py
│ │ ├── migrations
│ │ │ ├── 0001_initial.py
│ │ │ └── __init__.py
│ │ ├── models.py
│ │ ├── tests.py
│ │ └── views.py
│ ├── iotd
│ │ ├── __init__.py
│ │ ├── settings.py
│ │ ├── urls.py
│ │ └── wsgi.py
│ ├── manage.py
│ ├── static
│ │ ├── css
│ │ │ └── bootstrap.min.css
│ │ └── js
│ │ ├── bootstrap.min.js
│ │ └── jquery-1.11.0.min.js
│ └── templates
│ ├── base.html
│ └── images
│ └── home.html
├── requirements.txt
└── www
└── media
└── sitelogo.png
Inside that directory is a
config.yml file, which is a configuration file that is used to define certain parameters for your newly minted Beanstalk application.
At this point, if you type
eb console it will open up your default browser and navigate to the Elastic Beanstalk console. On the page, you should see one application (called image-of-the-day if you’re following along exactly), but no environments.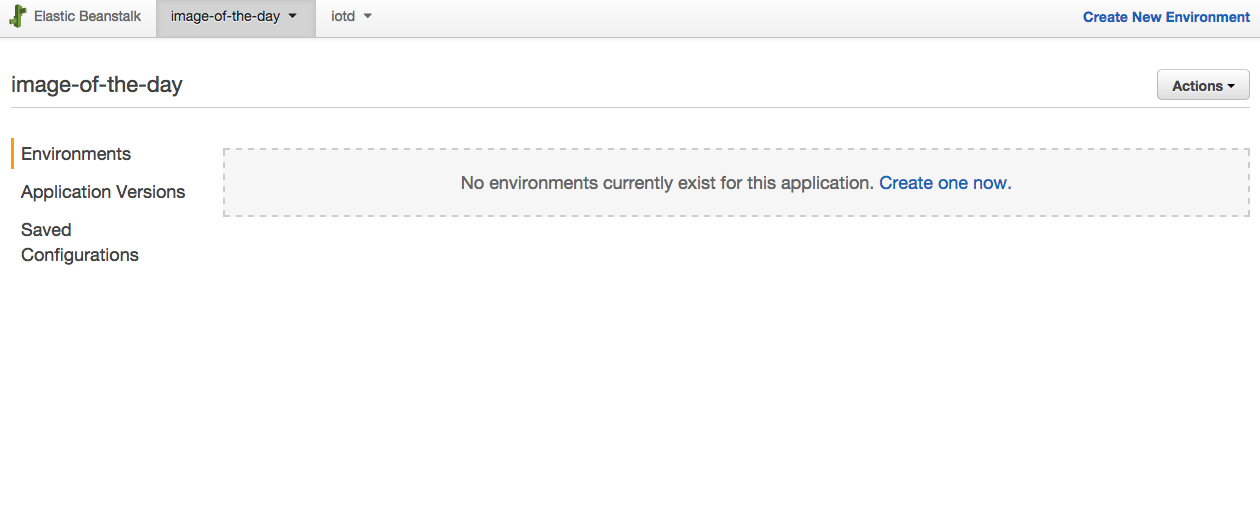
An application represents your code application and is what
eb init created for us. With Elastic Beanstalk, an application can have multiple environments (i.e., development, testing, staging, production). It is completely up to you how you want to configure/manage these environments. For simple Django applications I like to have the development environment on my laptop, then create a test and a production environment on Beanstalk.
Let’s get a test environment set up…
Configure EB – Create an Environment
Coming back to the terminal, in your project directory type:
$ eb create
Just like
eb init, this command will prompt you with a series of questions.
Environment Name
You should use a similar naming convention to what Amazon suggests - e.g., application_name-env_name - especially when/if you start hosting multiple applications with AWS. I used -
iod-test.
DNS CNAME prefix
When you deploy an app to Elastic Beanstalk you will automatically get a domain name like xxx.elasticbeanstalk.com.
DNS CNAME prefix is what you want to be used in place of xxx. Just go with the default.What happens now?
At this point
eb will actually create your environment for you. Be patient as this can take some time.If you do get an error creating the environment, like -aws.auth.client.error.ARCInstanceIdentityProfileNotFoundException- check that the credentials you are using have appropriate permissions to create the Beanstalk environment, as discussed earlier in this post.
Immediately after the environment is created,
eb will attempt to deploy your application, by copying all the code in your project directory to the new EC2 instance, running pip install -r requirements.txt in the process.
You should see a bunch of information about the environment being set up displayed to your screen, as well as information about
eb trying to deploy. You will also see some errors. In particular you should see these lines buried somewhere in the output:ERROR: Your requirements.txt is invalid. Snapshot your logs for details.
Don’t worry - It’s not really invalid. Check the logs for details:
$ eb logs
This will grab all the recent log files from the EC2 instance and output them to your terminal. It’s a lot of information so you may want to redirect the output to a file (
eb logs -z). Looking through the logs, you’ll see one log file named eb-activity.log:Error: pg_config executable not found.
The problem is that we tried to install
psycopy2 (the Postgres Python bindings), but we need the Postgres client drivers to be installed as well. Since they are not installed by default we need to install them first. Let’s fix that…Customizing the Deployment Process
eb will read custom .config files from a folder called “.ebextensions” at the root level of your project (“image-of-the-day” directory). These .config files allow you to install packages, run arbitrary commands and/or set environment variables. Files in the “.ebextensions” directory should conform to either JSON or YAML syntax and are executed in alphabetical order.Installing packages
The first thing we need to do is install some packages so that our
pip install command will complete successfully. To do this, let’s first create a file called .ebextensions/01_packages.config:packages:
yum:
git: []
postgresql93-devel: []
EC2 instances run Amazon Linux, which is a Redhat flavor, so we can use yum to install the packages that we need. For now, we are just going to install two packages - git and the Postgres client.
After creating that file to redeploy the application, we need to do the following:
$ git add .ebextensions/
$ git commit -m "added eb package configuration"
We have to commit the changes because the deployment command
eb deploy works off the latest commit, and will thus only be aware of our file changes after we commit them to git. (Do note though that we don’t have to push; we are working from our local copy…)
As you probably guessed, the next command is:
$ eb deploy
You should now see only one error:
INFO: Environment update is starting.
INFO: Deploying new version to instance(s).
ERROR: Your WSGIPath refers to a file that does not exist.
INFO: New application version was deployed to running EC2 instances.
INFO: Environment update completed successfully.
Let’s find out what’s happening…
Configuring our Python environment
EC2 instances in Beanstalk run Apache, and Apache will find our Python app according to the WSGIPATH that we have set. By default
eb assumes our wsgi file is called application.py. There are two ways of correcting this-
Option 1: Using environment-specific configuration settings
$ eb config
This command will open your default editor, editing a configuration file called .elasticbeanstalk/iod-test.env.yml. This file doesn’t actually exist locally;
eb pulled it down from the AWS servers and presented it to you so that you can change settings in it. If you make any changes to this pseudo-file and then save and exit, eb will update the corresponding settings in your Beanstalk environment.
If you search for the terms ‘WSGI’ in the file, and you should find a configuration section that looks like this:
aws:elasticbeanstalk:container:python:
NumProcesses: '1'
NumThreads: '15'
StaticFiles: /static/=static/
WSGIPath: application.py
Update the WSGIPath:
aws:elasticbeanstalk:container:python:
NumProcesses: '1'
NumThreads: '15'
StaticFiles: /static/=static/
WSGIPath: iotd/iotd/wsgi.py
And then you will have you WSGIPath set up correctly. If you then save the file and exit,
ebwill update the environment configuration automatically:Printing Status:
INFO: Environment update is starting.
INFO: Updating environment iod-test's configuration settings.
INFO: Successfully deployed new configuration to environment.
INFO: Environment update completed successfully.
The advantage to using the
eb config method to change settings is that you can specify different settings per environment. But you can also update settings using the same .config files that we were using before. This will use the same settings for each environment, as the .config files will be applied on deployment (after the settings from eb config have been applied).
Option 2: Using global configuration settings
To use the
.config file option, let’s create a new file called /.ebextensions/02_python.config:option_settings:
"aws:elasticbeanstalk:application:environment":
DJANGO_SETTINGS_MODULE: "iotd.settings"
"PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH"
"aws:elasticbeanstalk:container:python":
WSGIPath: iotd/iotd/wsgi.py
NumProcesses: 3
NumThreads: 20
"aws:elasticbeanstalk:container:python:staticfiles":
"/static/": "www/static/"
What’s happening?
DJANGO_SETTINGS_MODULE: "iotd.settings"- adds the path to the settings module."PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH"- updates ourPYTHONPATHso Python can find the modules in our application. (Note that the use of the full path is necessary.)WSGIPath: iotd/iotd/wsgi.pysets our WSGI Path.NumProcesses: 3andNumThreads: 20- updates the number of processes and threads used to run our WSGI application."/static/": "www/static/"sets our static files path.
Again, we can do a
git commit then an eb deploy to update these settings.
Next let’s add a database.
Configuring a Database
Try to view the deployed website:
$ eb open
This command will show the deployed application in your default browser. You should see a connection refused error:
OperationalError at /
could not connect to server: Connection refused
Is the server running on host "localhost" (127.0.0.1) and accepting
TCP/IP connections on port 5432?
This is because we haven’t set up a database yet. At this point
eb will set up your Beanstalk environment, but it doesn’t set up RDS (the database tier). We have to set that up manually.Database setup
Again, use
eb console to open up the Beanstalk configuration page.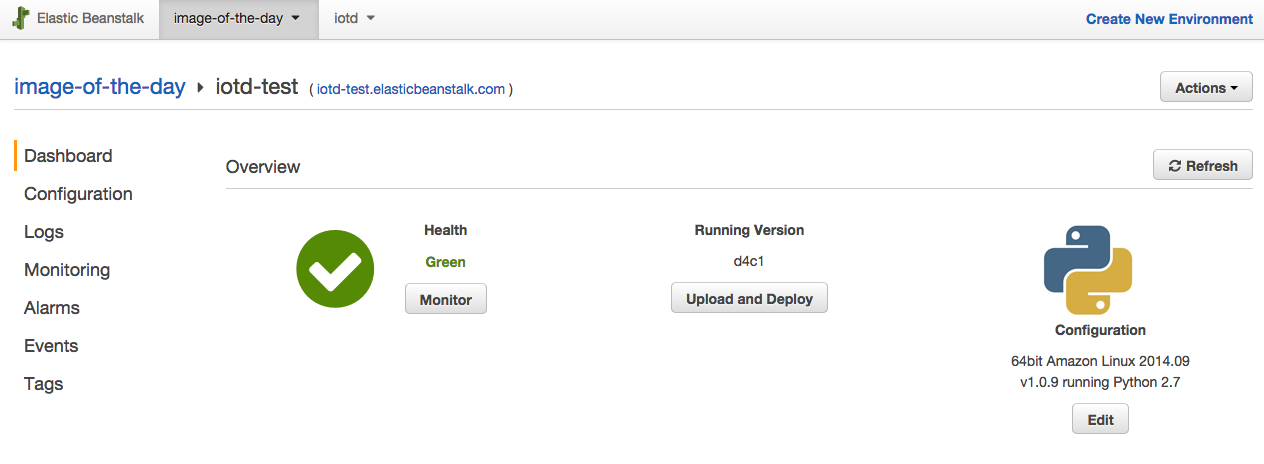
From there, do the following:
- Click the “Configuration” link.
- Scroll all the way to the bottom of the page, and then under the “Data Tier” section, click the link “create a new RDS database”.
- On the RDS setup page change the “DB Engine” to “postgres”.
- Add a “Master Username” and “Master Password”.
- Save the changes.
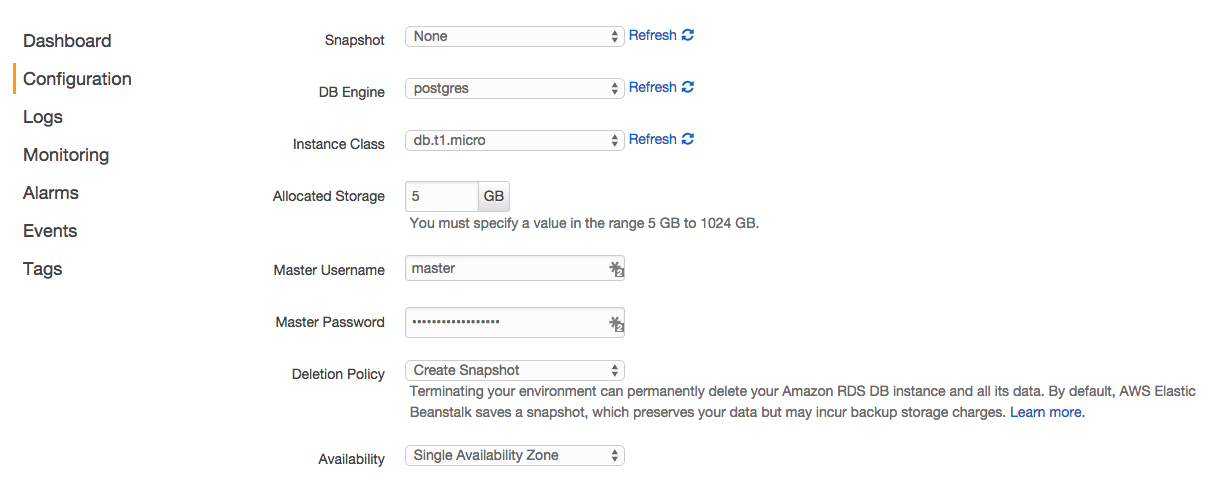
Beanstalk will create the RDS for you. Now we need to get our Django app to connect to the RDS. Beanstalk will help us out here by exposing a number of environment variables on the EC2 instances for us that detail how to connect to the Postgres server. So all we need to do is update our settings.py file to take advantage of those environment variables. Confirm that the
DATABASES configuration parameter reflects the following in settings.py:if 'RDS_DB_NAME' in os.environ:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': os.environ['RDS_DB_NAME'],
'USER': os.environ['RDS_USERNAME'],
'PASSWORD': os.environ['RDS_PASSWORD'],
'HOST': os.environ['RDS_HOSTNAME'],
'PORT': os.environ['RDS_PORT'],
}
}
else:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'iotd',
'USER': 'iotd',
'PASSWORD': 'iotd',
'HOST': 'localhost',
'PORT': '5432',
}
}
This simply says, “Use the environment variable settings if present, otherwise use our default development settings”. Simple.
Handling database migrations
With our database setup, we still need to make sure that migrations are ran so that the database table structure is correct. We can do that by modifying .ebextensions/02_python.config and adding the following lines at the top of the file:
container_commands:
01_migrate:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py migrate --noinput"
leader_only: true
container_commands allow you to run arbitrary commands after the application has been deployed on the EC2 instance. Because the EC2 instance is set up using a virtual environment, we must first activate that virtual environment before running our migrate command. Also the leader_only: true setting means, “Only run this command on the first instance when deploying to multiple instances”.
Don’t forget that our application makes use of Django’s admin, so we are going to need a superuser…
Create the Admin User
Unfortunately
createsuperuser doesn’t allow you to specify a password when using the --noinput option, so we will have to write our own command. Fortunately, Django makes it very easy to create custom commands.
Create the file iotd/images/management/commands/createsu.py:
from django.core.management.base import BaseCommand
from django.contrib.auth.models import User
class Command(BaseCommand):
def handle(self, *args, **options):
if not User.objects.filter(username="admin").exists():
User.objects.create_superuser("admin", "admin@admin.com", "admin")
Make sure you add the appropriate
__init__.py files as well:└─ management
├── __init__.py
└── commands
├── __init__.py
└── createsu.py
This file will allow you to run
python manage.py createsu, and it will create a superuser without prompting for a password. Feel free to expand the command to use environment variables or another means to allow you to change the password.
Once you have the command created, we can just add another command to our
container_commands section in .ebextensions/02_python.config:02_createsu:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py createsu"
leader_only: true
Before you test this out, let’s make sure our static files are all put in the correct place…
Static Files
Add one more command under
container_commands:03_collectstatic:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py collectstatic --noinput"
So the entire file looks like this:
container_commands:
01_migrate:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py migrate --noinput"
leader_only: true
02_createsu:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py createsu"
leader_only: true
03_collectstatic:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py collectstatic --noinput"
option_settings:
"aws:elasticbeanstalk:application:environment":
DJANGO_SETTINGS_MODULE: "iotd.settings"
"PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH"
"ALLOWED_HOSTS": ".elasticbeanstalk.com"
"aws:elasticbeanstalk:container:python":
WSGIPath: iotd/iotd/wsgi.py
NumProcesses: 3
NumThreads: 20
"aws:elasticbeanstalk:container:python:staticfiles":
"/static/": "www/static/"
We now need to ensure that the
STATIC_ROOT is set correctly in the settings.py file:STATIC_ROOT = os.path.join(BASE_DIR, "..", "www", "static")
STATIC_URL = '/static/'
Make sure you commit the
www directory to git so the static dir can be created. Then run eb deploy again, and you should now be in business:INFO: Environment update is starting.
INFO: Deploying new version to instance(s).
INFO: New application version was deployed to running EC2 instances.
INFO: Environment update completed successfully.
At this point you should be able to go to http://your_app_url/admin, log in, add an image, and then see that image displayed on the main page of your application.
Success!
Using S3 for Media Storage
With this setup, each time we deploy again, we will lose all of our uploaded images. Why? Well, when you run
eb deploy, a fresh instance is spun up for you. This is not what we want since we will then have entries in the database for the images, but no associated images. The solution is to store the media files in Amazon Simple Storage Service (Amazon S3) instead of on the EC2 instance itself.
You will need to:
- Create a bucket
- Grab your user’s ARN (Amazon Resource Name)
- Add bucket permissions
- Configure your Django app to use S3 to serve your static files
Since there are good write ups on this already, I’ll just point you to my favorite: Using Amazon S3 to store you Django Static and Media Files
Apache Config
Since we are using Apache with Beanstalk, we probably want to set up Apache to (among other things) enable gzip compression so files are downloaded faster by the clients. That can be done with
container_commands. Create a new file .ebextensions/03_apache.config and add the following:container_commands:
01_setup_apache:
command: "cp .ebextensions/enable_mod_deflate.conf /etc/httpd/conf.d/enable_mod_deflate.conf"
Then you need to create the file
.ebextensions/enable_mod_deflate.conf:# mod_deflate configuration
<IfModule mod_deflate.c>
# Restrict compression to these MIME types
AddOutputFilterByType DEFLATE text/plain
AddOutputFilterByType DEFLATE text/html
AddOutputFilterByType DEFLATE application/xhtml+xml
AddOutputFilterByType DEFLATE text/xml
AddOutputFilterByType DEFLATE application/xml
AddOutputFilterByType DEFLATE application/xml+rss
AddOutputFilterByType DEFLATE application/x-javascript
AddOutputFilterByType DEFLATE text/javascript
AddOutputFilterByType DEFLATE text/css
# Level of compression (Highest 9 - Lowest 1)
DeflateCompressionLevel 9
# Netscape 4.x has some problems.
BrowserMatch ^Mozilla/4 gzip-only-text/html
# Netscape 4.06-4.08 have some more problems
BrowserMatch ^Mozilla/4\.0[678] no-gzip
# MSIE masquerades as Netscape, but it is fine
BrowserMatch \bMSI[E] !no-gzip !gzip-only-text/html
<IfModule mod_headers.c>
# Make sure proxies don't deliver the wrong content
Header append Vary User-Agent env=!dont-vary
</IfModule>
</IfModule>
Doing this will enable gzip compression, which should help with the size of the files you’re downloading. You could also use the same strategy to automatically minify and combine your CSS/JS and do any other preprocessing you need to do.
Troubleshooting
Don’t forget the very helpful
eb ssh command, which will get you into the EC2 instance so you can poke around and see what’s going on. When troubleshooting, there are a few directories you should be aware of:/opt/python- Root of where you application will end up./opt/python/current/app- The current application that is hosted in the environment./opt/python/on-deck/app- The app is initially put in on-deck and then, after all the deployment is complete, it will be moved tocurrent. If you are getting failures in yourcontainer_commands, check out out theon-deckfolder and not thecurrentfolder./opt/python/current/env- All the env variables thatebwill set up for you. If you are trying to reproduce an error, you may first need tosource /opt/python/current/envto get things set up as they would be when eb deploy is running.opt/python/run/venv- The virtual env used by your application; you will also need to runsource /opt/python/run/venv/bin/activateif you are trying to reproduce an error
Conclusion
Deploying to Elastic Beanstalk can be a bit daunting at first, but once you understand where all the parts are and how things work, it’s actually pretty easy and extremely flexible. It also gives you an environment that will scale automatically as your usage grows. Hopefully by now you have enough to be dangerous! Good luck on your next Beanstalk deployment.